Generating robust and reliable data resources employing the most contemporary technologies, formidable software, and expert support services to help our clients convert data insights into tangible actions.

At the core of our enterprise integration solution is formidable software designed for efficient information processing. This platform, which serves as the engine behind our market-leading solution, Onpoint CDM, provides tools for secure submission, cleanses and standardizes incoming data, performs rigorous quality assurance procedures, and integrates and consolidates disparate data sets. The end goal: downstream data enrichment and follow-on analytics.
Data Collection: Our systems have been handling secure submissions of healthcare data – commercial, Medicaid, and Medicare alike – for nearly 15 years across several states and more than 250 carriers. With its superior data processing and performance capabilities, our data collection solution sets the foundation for the delivery of a reliable resource in support of advanced analytics.
Data Submission Portal: Our Data Operations team supports each of our clients and their submitters through a secure online interface: Onpoint CDM. There, credentialed users are offered a wide range of tools to help keep them informed – from helpful links and collection rules and regulation documentation, to data submission guides, FAQs, and announcements.
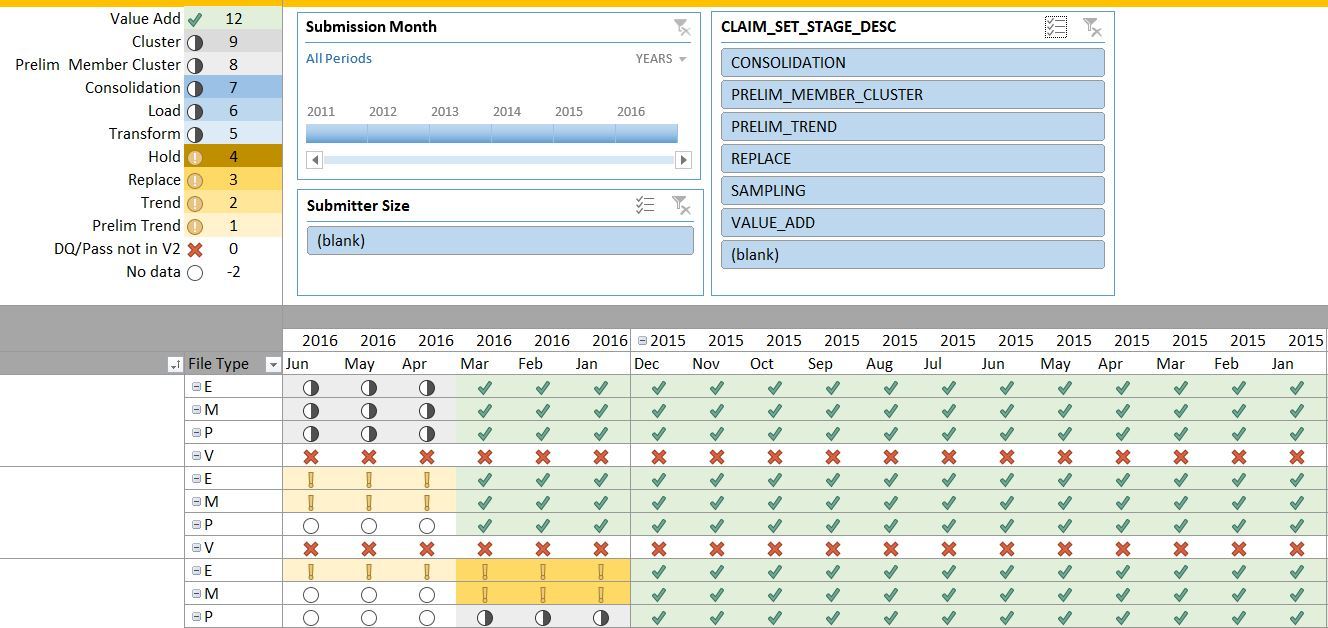 Data Quality Validations: To ensure that our clients' data will meet their end users' analytic needs, we've programmed thousands of validations in our data quality library. Refreshed on demand and in real time, Onpoint CDM delivers the results of these processes to credentialed users through a variety of parameter-driven status reports, verifying the integrity and validity of the submitted data, as well as the consistency and completeness of elements across data types and time.
Data Quality Validations: To ensure that our clients' data will meet their end users' analytic needs, we've programmed thousands of validations in our data quality library. Refreshed on demand and in real time, Onpoint CDM delivers the results of these processes to credentialed users through a variety of parameter-driven status reports, verifying the integrity and validity of the submitted data, as well as the consistency and completeness of elements across data types and time.
Public/Private Payer Integration: Our staff have deep expertise in the integration of public and private payer data sources, expertly mapping and merging Medicaid and Medicare data with commercial streams, applying customized field-level validations, adjustment algorithms, and flag assignments to support analytics.
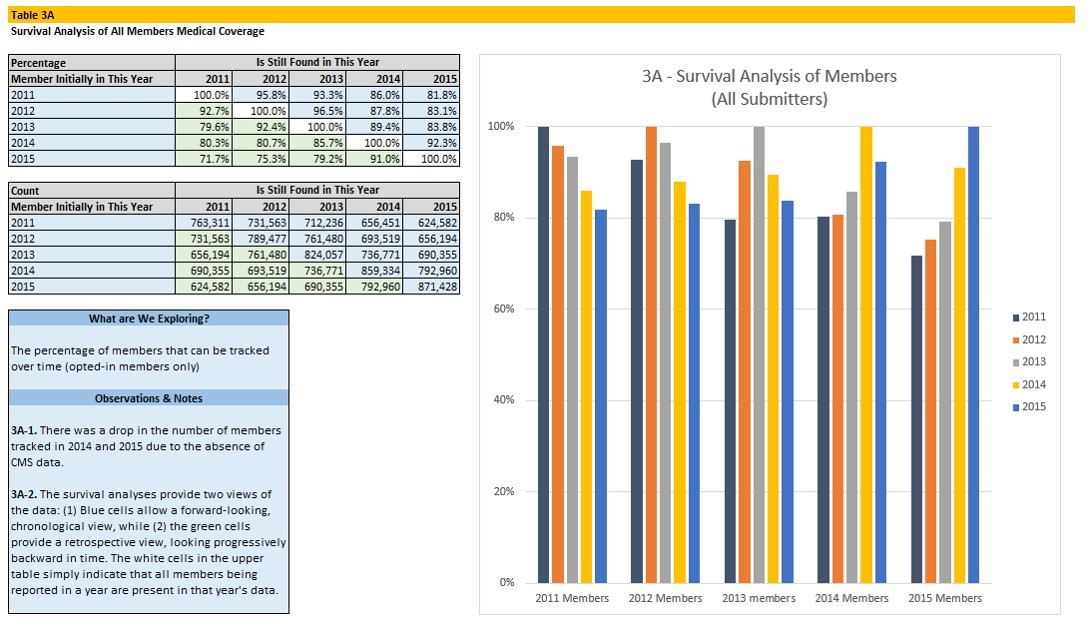
Non-Claims Data Linkage: With linked data sources more powerful than any data set alone, we regularly integrate our clients’ claims-based repositories with non-claims data sources, including hospital discharge databases, public health/birth/death registries, cancer surveillance repositories, electronic health records, chronic disease program data sets, clinical registries, and survey data.
Data Warehousing: Our operational data store uses a highly normalized, relational database design to facilitate efficient processing of data transactions. The resulting data model is optimized for downstream analytics and reporting and designed with the versatility to meet evolving client needs.
Data Security: We take data security as seriously as our clients. Operating from a SSAE 16 / SOC II hardened data center, we remain in full security compliance with HIPAA and HITECH and feature certification from the CMS Qualified Entity Certification Program (QECP). On top of that, Onpoint has earned Certified status for information security by the Health Information Trust (HITRUST) Alliance. With the HITRUST CSF Certified Status, Onpoint meets key healthcare regulations and requirements for protecting and securing sensitive private healthcare information.
Onpoint’s enterprise integration solution is constantly optimized to provide superior data processing and performance, enabling the creation of a robust set of value-add services, including attribution, flag assignment, group assignment, identity resolution, performance measurement, and risk scoring.
Attribution: Member-to-provider, provider-to-practice, and practice-to-organization attribution algorithms are interconnected assignments that help researchers evaluate the delivery and quality of care at each level of treatment.
Flag Assignment: Analytic flags assist researchers and analysts in identifying subsets of records that are of particular interest. Standard assignments include inpatient discharge, claim type, aggregated age groupings, and chronic condition flags. Our inpatient discharge flag, for example, uses a sophisticated algorithm to cluster multi-claim inpatient stays into a single institutional stay for accuracy.
Group Assignment: From CRGs and DRGs to ERGs and PFEs, to BETOS and Red Book®, our extensive experience applying grouper software to our clients' data sets helps support a wide array of advanced analytics and reporting solutions such as the examination of preference-sensitive conditions to reduce unnecessary care and associated cost, the assessment of cost and quality at episode and specialty levels, and the bundling of provider-based payments to focus on event-based episodes.
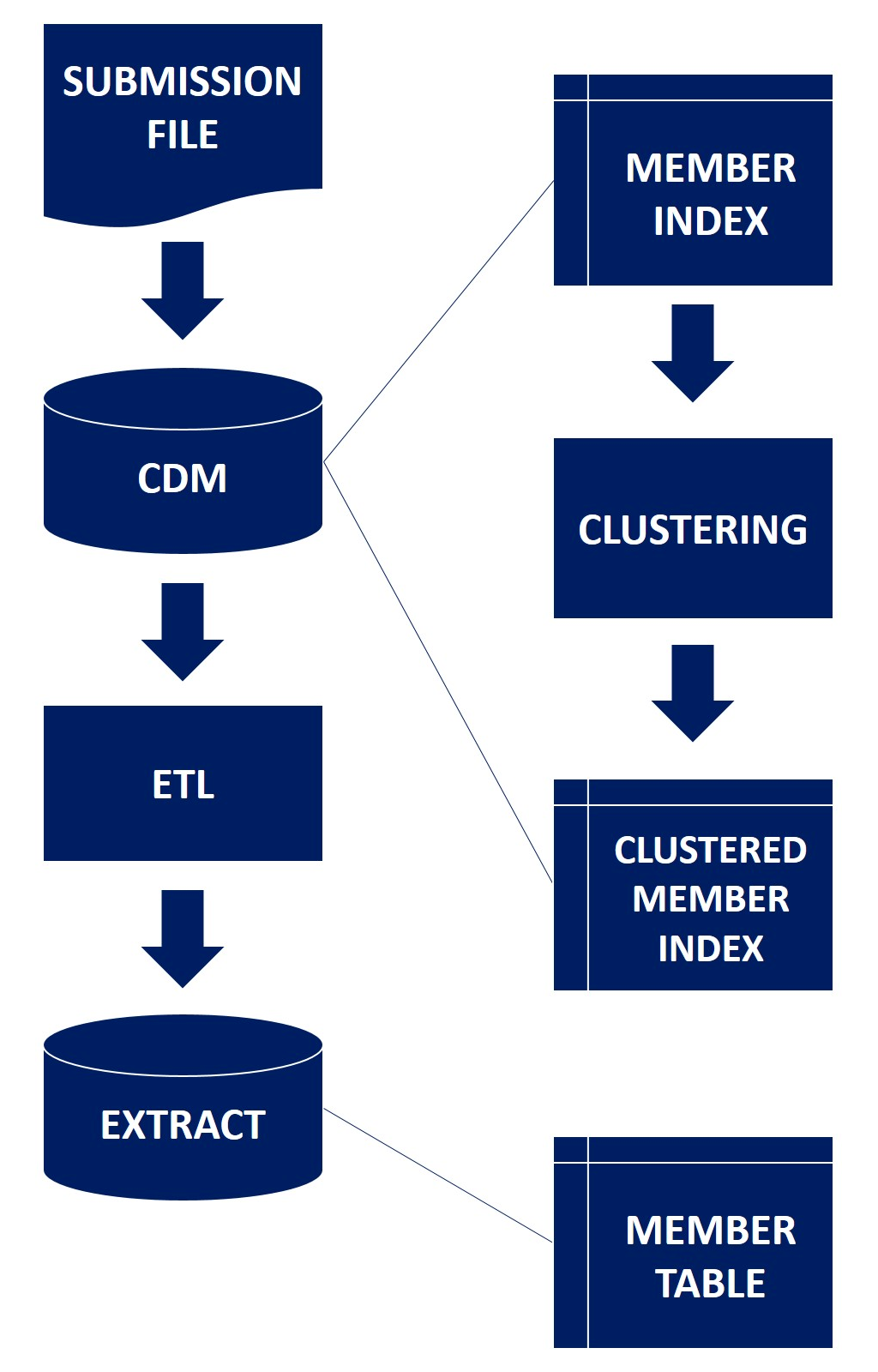 Identity Resolution: Tracking individual patients and providers across time and health plans is critical to accurate analysis. That's why our team performs this service through the construction of advanced master patient and provider indices, which span a complex series of algorithms and automated linkage steps that rely, first and foremost, on the quality of the underlying data.
Identity Resolution: Tracking individual patients and providers across time and health plans is critical to accurate analysis. That's why our team performs this service through the construction of advanced master patient and provider indices, which span a complex series of algorithms and automated linkage steps that rely, first and foremost, on the quality of the underlying data.
Performance Measurement: Our Measures Engine library currently has more than 100 claims- and clinical-based measures programmed and ready to run on our clients' data sets. While the majority of those measures are supported by HEDIS, NQF, IHA, AHRQ, and HealthPartners specifications, where national standards don’t yet exist Onpoint has developed measures and their respective methodologies to address our clients’ interests and varying needs.
Risk Scoring: A wide variety of attributes, including demographic, major payer type, and health status information, serve as the primary inputs for the risk-adjustment methodologies employed by Onpoint in generating our clients' analytic and reporting solutions. Lower- and upper-confidence intervals of 95% often supplement our clients' reporting to help them deduce the statistical significance of the risk-adjusted rates.
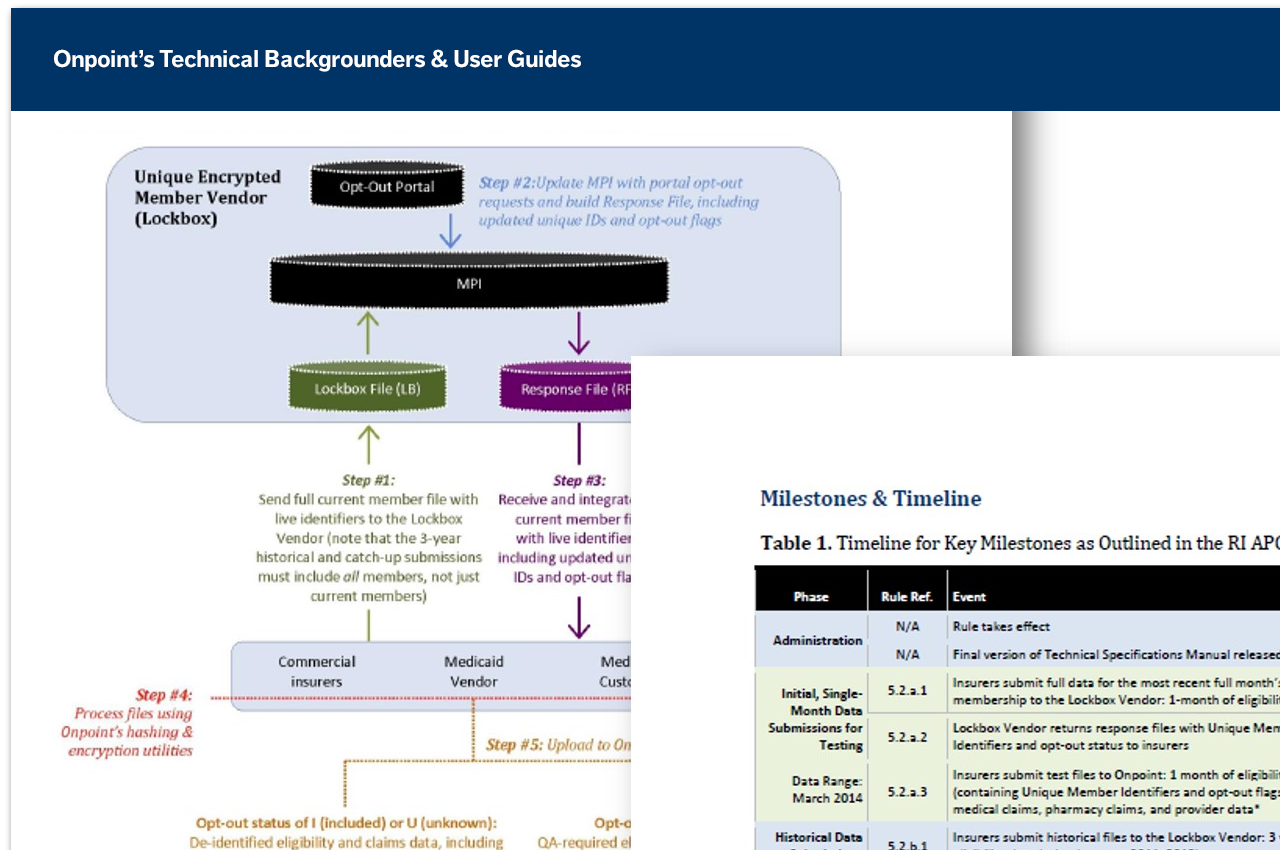
A unique know-how of health data and its inherent limitations is key to ensuring the success of our clients’ data collection efforts. Our staff, expert in coding standards, claims adjudication processes, research methods, and privacy and security laws, assist our end-user community in better understanding data integration and enhancement activities to ensure complete buy-in of the data we deliver.
End-User Documentation: To build a transparent knowledge base for our end-user community, our team of project leads and supporting analysts produce a wide array of documentation, including data dictionaries, user guides, technical backgrounders, and data FAQs.
Online Collaboration: Onpoint’s interactive Collaboration Zone, powered by Microsoft SharePoint, is a secure, online hub tailored to the specific needs of clients and their end users, enabling stakeholders to share documentation, access key communications, exchange questions and ideas, and stay up to date through an intuitive user-friendly environment.
Submitter Outreach: Implementation of a client’s data collection initiative involves extensive collaboration with submitters – new and experienced alike – to initiate data transmission activities and to resolve data quality issues identified throughout the process. 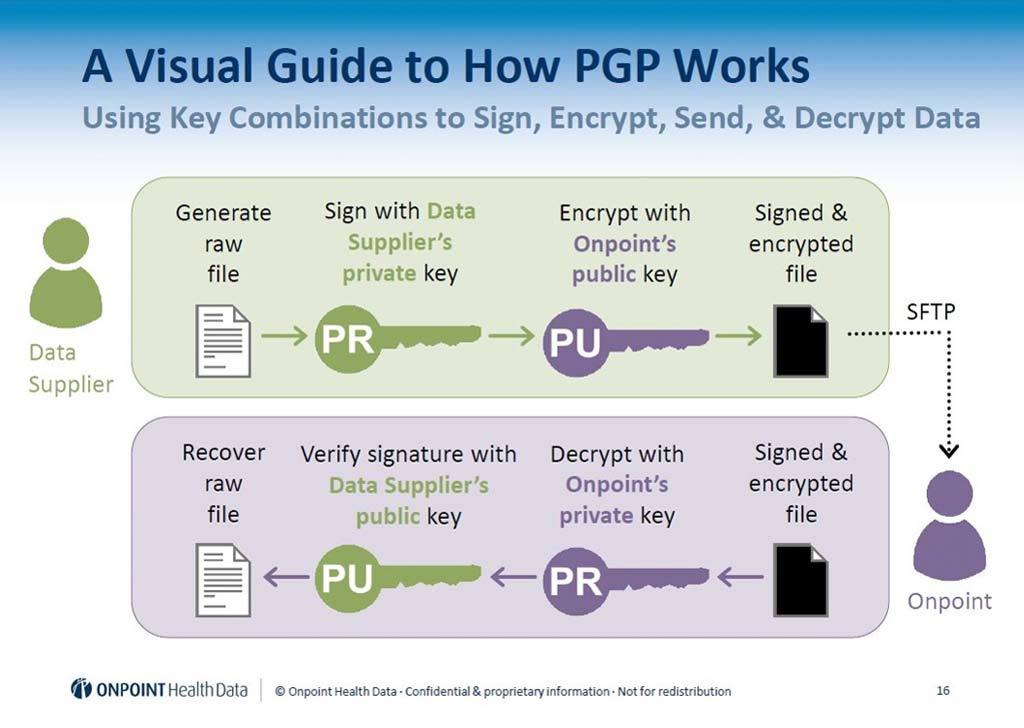 Factors critical to this initial phase include proactive communication, live-time dissemination of data quality reports, robust documentation, and continuous training and support.
Factors critical to this initial phase include proactive communication, live-time dissemination of data quality reports, robust documentation, and continuous training and support.
Tailored Training Programs: Online webinar trainings for clients and their stakeholders support knowledge transfer and cross-training needs on the data and its analytic use. Standard sessions include review of data and schema processes, end-user documentation, quality assurance procedures, and standard and client-specific value-add services.